class: center, middle # Lecture 10: ## From notebooks to projects <br/> <br/> .bold[Andrei Bursuc ] <br/> .bold[.gray[valeo]_.ai_] <br/> --- # Outline - Under the hood - Tools for visualization and logging - Example project --- class: center, middle # GPUs .center[<img src="images/part10/nvidia_titan_xp.jpg" style="width: 700px;" />] --- # CPU vs GPU <br/> .left[ .center[CPU] <br/> .center[<img src="images/part10/cpu.png" style="width: 350px;" />] ] .right[ .center[GPU] <br/> .center[<img src="images/part10/nvidia_tesla_v100.jpg" style="width: 500px;" />] ] --- # CPU vs GPU .left-column[ - CPU: + fewer cores; each core is faster and more powerful + useful for sequential tasks ] .right-column[ - GPU: + more cores; each core is slower and weaker + great for parallel tasks ] .reset-column[] .center.width-70[] --- # CPU vs GPU .left-column[ - CPU: + fewer cores; each core is faster and more powerful + useful for sequential tasks ] .right-column[ - GPU: + more cores; each core is slower and weaker + great for parallel tasks ] .reset-column[] <br/> | | Cores | Clock Speed | Memory | Price | Speed | |---|---|---|---|---| | .bold[CPU] <br/> Intel Core i7-7700k| $4$ <br/> (8 threads with hyperthreading) | $4.2$ Ghz | System RAM | $339$ € | $\sim540$ GFLOPs FP32 | | .bold[GPU] <br/>Nvidia GTX 1080 Ti| $3584$ | $1.6$ Ghz | $11$ GB GDDR5X | $699$ € | $\sim11.4$ TFLOPs FP32 | --- # CPU vs GPU .center.width-70[] .left-column[ - SP = single precision, 32 bits / 4 bytes ] .right-column[ - DP = double precision, 64 bits / 8 bytes ] --- # CPU vs GPU .center[<img src="images/part10/gpu_benchmark.png" style="width: 700px;" />] .citation[Benchmarking State-of-the-Art Deep Learning Software Tools, Shi et al., 2016] --- # CPU vs GPU .center.width-80[] - more benchmarks available at [https://github.com/jcjohnson/cnn-benchmarks](https://github.com/jcjohnson/cnn-benchmarks) .credit[Figure credit: J. Johnson] --- # CPU vs GPU .center.width-80[] - more benchmarks available at [https://github.com/jcjohnson/cnn-benchmarks](https://github.com/jcjohnson/cnn-benchmarks) .credit[Figure credit: J. Johnson] --- # CPU vs GPU .center.width-80[] .credit[Figure credit: J. Johnson] --- # CPU vs GPU <br/> | | Cores | Clock Speed | Memory | Price | Speed | |---|---|---|---|---| | .bold[CPU] <br/> Intel Core i7-7700k| $4$ <br/> (8 threads with hyperthreading) | $4.2$ Ghz | System RAM | $339$ € | $\sim540$ GFLOPs FP32 | | .bold[GPU] <br/>Nvidia GTX 1080 Ti| $3584$ | $1.6$ Ghz | $11$ GB GDDR5X | $699$ € | $\sim11.4$ TFLOPs FP32 | | .bold[GPU] <br/> Nvidia Titan V| $5120$ | $1.5$ Ghz | $12$ GB HBM2 | $2999$ € | $\sim14$ TFLOPs FP32 <br/> $\sim 112$ TFLOPs FP16 | --- # CPU vs GPU .center.width-80[] .credit[Figure credit: J. Johnson] --- # CPU vs GPU <br/> | | Cores | Clock Speed | Memory | Price | Speed | |---|---|---|---|---| | .bold[CPU] <br/> Intel Core i7-7700k| $4$ <br/> (8 threads with hyperthreading) | $4.2$ Ghz | System RAM | $339$ € | $\sim540$ GFLOPs FP32 | | .bold[GPU] <br/>Nvidia GTX 1080 Ti| $3584$ | $1.6$ Ghz | $11$ GB GDDR5X | $699$ € | $\sim11.4$ TFLOPs FP32 | | .bold[GPU] <br/> Nvidia Titan V| $5120$ | $1.5$ Ghz | $12$ GB HBM2 | $2999$ € | $\sim14$ TFLOPs FP32 <br/> $\sim 112$ TFLOPs FP16 | | .bold[TPU] <br/> Google Cloud TPUS| - | - | $64$ GB HBM | $6.5$ $/hour | $\sim180$ TFLOPs <br/> with 4 stacked TPUs| -- count: false <br/> .tiny[Some advice for trying to setup your GPU at home: http://timdettmers.com/2018/11/05/which-gpu-for-deep-learning/] --- # The ImageNet sprint .left-column[ .italic[aka] Who's the _Usain Bolt_ of Deep Learning? ] .right-column[.center.width-50[] ] .reset-column[ ] .center.width-70[] .citation[DAWNBench: https://dawn.cs.stanford.edu/benchmark/] --- # The ImageNet sprint ### Current SoTA - Train ResNet-50 on ImageNet to $76.3\%$ accuracy in $2.2$ minutes on a 1024-chip TPU v3 Pod - Training throughput of over $1.05\text{M}$ images/second and no accuracy drop. .center.width-50[] .citation[Image Classification at Supercomputer Scale, C. Ying et al., arXiv 2018] --- # The ImageNet sprint .left-column[ .italic[aka] Who's the _Usain Bolt_ of Deep Learning? ] .right-column[.center.width-50[] ] .reset-column[ ] .center.width-70[] .citation[DAWNBench: https://dawn.cs.stanford.edu/benchmark/] --- # The ImageNet sprint .left-column[ .italic[aka] Who's the _Usain Bolt_ of Deep Learning? ] .right-column[.center.width-50[] ] .reset-column[ ] .center.width-70[] .citation[DAWNBench: https://dawn.cs.stanford.edu/benchmark/] --- # System .center[<img src="images/part10/system_1.png" style="width: 700px;" />] .credit[Figure credit: F. Fleuret] --- # System .center[<img src="images/part10/system_2.png" style="width: 700px;" />] .credit[Figure credit: F. Fleuret] --- # System .center[<img src="images/part10/system_3.png" style="width: 700px;" />] .credit[Figure credit: F. Fleuret] --- # System .center[<img src="images/part10/system_4.png" style="width: 700px;" />] .credit[Figure credit: F. Fleuret] --- # System .center[<img src="images/part10/system_5.png" style="width: 700px;" />] .credit[Figure credit: F. Fleuret] --- # System .center[<img src="images/part10/system_6.png" style="width: 700px;" />] .credit[Figure credit: F. Fleuret] --- # System .center[<img src="images/part10/system_7.png" style="width: 700px;" />] .credit[Figure credit: F. Fleuret] --- # Programming GPUs - NVIDIA GPUs are programmed through .bold[CUDA] (_Compute Unified Device Architecture_) -- count:false - The alternative is .bold[OpenCL], supported by several manufacturers but with significant less investments than Nvidia -- count: false - Recently .bold[HIP](_Heterogeneous-compute Interface for Portability_) converts CUDA code to C++ code running on AMD GPus -- count:false - Google developed their own processor for deep learning .bold[TPU] (_Tensor Processing Unit_) with great flops/watt performance. It's for in-house use and it will be soon PyTorch-compatible. -- count:false - Nvidia and CUDA are dominating the field by far, though some alternatives start emerging: Intel Nervana, GraphCore, Groq, etc. --- # Libraries The interface between frameworks (PyTorch, TensorFlow) with the computational backend (CPU or GPU) is ensured by a couple of libraries -- count: false - BLAS (_Basic Linear Algebra Subprograms_): vector/matrix products, and the cuBLAS implementation for NVIDIA GPUs - LAPACK (_Linear Algebra Package_): linear system solving, Eigen-decomposition, etc. - cuDNN (_NVIDIA CUDA Deep Neural Network library_) computations specific to deep-learning on NVIDIA GPUs. --- # GPUs in pytorch Tensors of torch.cuda types are in the GPU memory. Operations on them are done by the GPU and resulting tensors are stored in its memory. -- count: false Checking if GPU exists on the machine and can be used ```py >>> torch.cuda.is_available() ``` -- count: false The device can be specified when at `Tensor` creation. ```py >>> x = torch.zeros(10, 10) >>> x.device device(type='cpu') >>> x = torch.zeros(10, 10, device = torch.device('cuda')) >>> x.device device(type='cuda', index=0) >>> x = torch.zeros(10, 10, device = torch.device('cuda:1')) >>> x.device device(type='cuda', index=1) ``` --- # GPUs in pytorch Moving Tensors between CPU and GPU ```py >>> x = torch.zeros(10, 10) >>> x.to('cuda') ... >>> x.to('cpu') ... >>> x.cuda() ... >>> x.cpu() ... ``` -- count:false Moving data between the CPU and the GPU memories is far slower than moving it inside the GPU memory. --- # GPUs in pytorch Operations maintain the types and devices of the tensors. You do not need to worry about making your code generic regarding these aspects. Most of the functions available on the CPU are over-rided on the GPU --- # GPUs in pytorch Operations cannot mix different tensor types (CPU vs. GPU, or different numerical types); except `copy_()` ```py >>> x = torch.zeros(2, 3) >>> y = torch.zeros(2, 3).fill_(4).cuda() >>> x.copy_(y) tensor([[ 4., 4., 4.], [ 4., 4., 4.]]) >>> x + y Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: Expected object of type torch.FloatTensor but found type torch.cuda.FloatTensor for argument #3 'other' ``` --- # GPUs in pytorch A simple manner for using multiple GPUs is to wrap the model in `nn.DataParallel`. -- count:false `nn.DataParallel`: + generates instances of the current model and sends them to all GPUs + splits the input mini-batch in as many new mini-batches as indicated GPUs + regroups by concatenation results from all GPUs --- # GPUs in pytorch .left-column[ `nn.DataParallel`: ```py class EmptyNet(nn.Module): def __init__(self, m): super(EmptyNet, self).__init__() self.m = m def forward(self, x): print('EmptyNet.forward', x.size(), x.device) return self.m(x) ``` ] .right-column[ ] --- # GPUs in pytorch .left-column[ `nn.DataParallel`: ```py class EmptyNet(nn.Module): def __init__(self, m): super(EmptyNet, self).__init__() self.m = m def forward(self, x): print('EmptyNet.forward', x.size(), x.device) return self.m(x) ``` ] .right-column[ ```py x = torch.empty(50, 10).normal_() model = EmptyNet(nn.Linear(10, 5)) print('On CPU') y = model(x) x = x.cuda() model.cuda() print('On GPU w/o nn.DataParallel') y = model(x) print('On GPU w/ nn.DataParallel') parallel_model = nn.DataParallel(model) y = parallel_model(x) ``` Running on a machine with two GPUs: ```py # On CPU EmpytNet.forward torch.Size([50, 10]) cpu # On GPU w/o nn.DataParallel EmpytNet.forward torch.Size([50, 10]) cuda:0 # On GPU w/ nn.DataParallel EmpytNet.forward torch.Size([25, 10]) cuda:0 EmpytNet.forward torch.Size([25, 10]) cuda:1 ``` ] --- class: middle # Keeping track of experiments and data visualization --- # Visdom .center.width-70[] .citation[Visdom: https://github.com/facebookresearch/visdom] --- # Visdom .left-column[ ```py from visdom import Visdom viz = Visdom(port=8030, server='http://localhost') # matplotlib demo: try: import matplotlib.pyplot as plt plt.plot([1, 23, 2, 4]) plt.ylabel('some numbers') viz.matplot(plt) except BaseException as err: print('Skipped matplotlib example') print('Error message: ', err) # histogram viz.histogram(X=np.random.rand(10000), opts=dict(numbins=20)) ``` ] .right-column[ ```py viz.bar( X=np.random.rand(20, 3), opts=dict( stacked=False, legend=['The Netherlands', 'France', 'United States'] ) ) # image demo viz.image( np.random.rand(3, 512, 256), opts=dict(title='Random!', caption='How random.'), ) # grid of images viz.images( np.random.randn(20, 3, 64, 64), opts=dict(title='Random images', caption='How random.') ) ``` ] .citation[Visdom: https://github.com/facebookresearch/visdom] --- # Visdom Pros: - lightweight and easy to deploy - a lot of functionalities available by default - sessions can be saved Cons: - you must manually define/compute/plot the things you have to have displayed .citation[Visdom: https://github.com/facebookresearch/visdom] --- # Tensorboard <!-- .center.width-60[] --> .center.width-80[] .citation[tensorboardX: https://github.com/lanpa/tensorboardX] --- # Tensorboard .left-column[ .center.width-80[] ] .right-column[ .center.width-80[] ] .citation[tensorboardX: https://github.com/lanpa/tensorboardX] --- ```py from tensorboardX import SummaryWriter resnet18 = models.resnet18(False) writer = SummaryWriter() ... dummy_s1 = torch.rand(1) dummy_s2 = torch.rand(1) writer.add_scalar('data/scalar1', dummy_s1[0], n_iter) writer.add_scalar('data/scalar2', dummy_s2[0], n_iter) writer.add_scalars('data/scalar_group', {'xsinx': n_iter * np.sin(n_iter), 'xcosx': n_iter * np.cos(n_iter), 'arctanx': np.arctan(n_iter)}, n_iter) if n_iter % 10 == 0: writer.add_image('Image', x, n_iter) writer.add_text('Text', 'text logged at step:' + str(n_iter), n_iter) for name, param in resnet18.named_parameters(): writer.add_histogram(name, param.clone().cpu().data.numpy(), n_iter) ... writer.add_embedding(features, metadata=label, label_img=images.unsqueeze(1)) # export scalar data to JSON for external processing writer.export_scalars_to_json("./all_scalars.json") writer.close() ``` .citation[tensorboardX: https://github.com/lanpa/tensorboardX] --- # Tensorboard .left-column[ Pros: - a lot of functionalities - less manual intervention required Cons: - can become quickly heavyweight with computations - not compatible with many situations ] .right-column[ .center.width-80[] ] .citation[tensorboardX: https://github.com/lanpa/tensorboardX] --- # pytorchviz .center.width-70[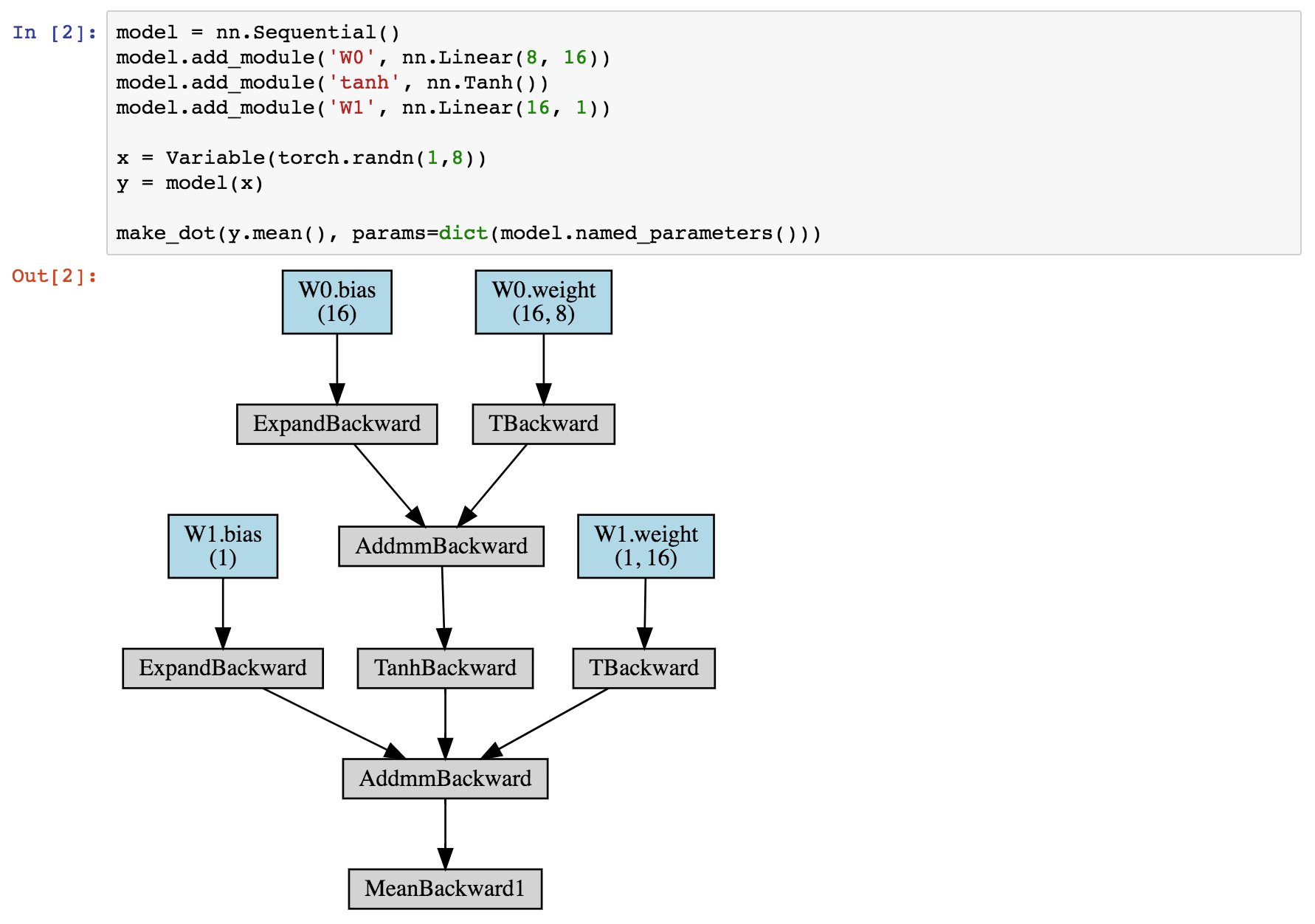] .citation[pytorchviz: https://github.com/szagoruyko/pytorchviz] --- class: end-slide, center count: false The end.